Arc Raiders sépare enfin les psychopathes des petits nouveaux
Je me suis fait offrir Arc Raiders pour Noël et je vous avoue que je ne comprends rien. En deux-trois parties, j'ai eu le temps de me faire démonter par des joueurs qui avaient visiblement passé leur réveillon à farmer du loot pendant que moi je cherchais encore comment ouvrir mon inventaire. Bref, super ambiance.

Arc Raiders, l'extraction shooter d'Embark Studios
Du coup, quand je suis tombé sur cette actu, ça m'a un peu rassuré. Embark Studios vient en effet de confirmer ce que la communauté soupçonnait depuis un moment : le jeu utilise bien un système de matchmaking basé sur l'agressivité. En gros, si vous êtes du genre à tirer sur tout ce qui bouge, vous serez matchés avec d'autres psychopathes du PvP. Et si comme moi vous préférez looter tranquillou sans vous faire exploser la tronche toutes les deux minutes, vous croiserez des joueurs plus... pacifiques.
Patrick Söderlund, le CEO d'Embark Studios, a expliqué le truc dans une interview avec Games Beat que voici :
Et d'après ce qu'il raconte, la hiérarchie du matchmaking fonctionne comme ça : d'abord le skill (votre niveau de jeu), ensuite le type de groupe (solo, duo ou trio), et enfin votre tendance PvP ou PvE. Le système analyse si vous êtes plutôt du genre à éviter les conflits ou à foncer dans le tas, puis vous met avec des joueurs au comportement similaire.
Bon, Söderlund a quand même précisé que "ce n'est pas une science exacte". Genre, si vous ne faites que riposter quand on vous attaque, est-ce que le système vous considère comme agressif ? Parce que techniquement, vous avez quand même buté quelqu'un...
En tout cas, ça fait plaisir d'avoir enfin une confirmation officielle ! Les joueurs présents sur Reddit vont enfin pouvoir arrêter de se disputer à ce sujet !

Du loot, des robots géants, et les autres joueurs... tout un programme !
Et pour ceux qui débarquent comme moi, sachez que les extraction shooters c'est un genre où vous débarquez sur une map, vous ramassez du stuff, et vous essayez de vous extraire sans tout perdre. Sauf que contrairement à un jeu de survie classique, les autres joueurs peuvent vous tomber dessus à tout moment. D'où l'importance d'un bon matchmaking pour limiter les chances que les débutants se fassent massacrer par des vétérans.
Bref, je vais peut-être pouvoir retourner sur Arc Raiders sans me faire one-shot dans les 30 premières secondes. Enfin, en théorie, parce qu'en pratique je suis quand même nul à chier, il va falloir que je me tape quelques tutos pour comprendre de quoi il en retourne ^^.
Unminus - De la musique gratuite pour vos projets (même commerciaux)
Si vous cherchez de la musique pour vos vidéos YouTube, vos podcasts ou même vos apps, vous savez que c'est souvent la galère. Soit vous payez des royalties à n'en plus finir, soit vous vous tapez des morceaux sous licence tellement restrictive que vous ne savez même plus ce que vous avez le droit de faire avec !
Hé bien ça tombe bien car je suis tombé sur Unminus et vous allez voir, c'est pas mal.
Il s'agit d'un site qui propose de la musique gratuite pour la plupart des usages, y compris commerciaux. Pas de pub qui vous explose la tronche, pas de conditions tordues, mais juste du son que vous pouvez télécharger et utiliser dans le cadre de leur licence ! C'est le modèle Unsplash appliqué à la musique, avec le slogan "No Rules. No Ads. Yes Artists."
Pour faire votre sélection, vous pouvez filtrer par humeur : Calm, Happy, Cool, Motivation, Sad, Bizarre, Aggressive...etc. Chaque piste affiche le BPM, le genre et même si c'est instrumental ou pas. Pratique quand vous cherchez un morceau précis pour caler sous votre intro de podcast ou une scène de votre court métrage.

Au niveau de la licence, ce n'est pas du CC0 comme on pourrait le croire. En réalité, Unminus a sa propre licence qui autorise l'usage commercial et non-commercial, les modifications (vous pouvez chanter dessus, découper, allonger, compresser...etc.), et même monétiser vos vidéos YouTube. Par contre, impossible de revendre la musique telle quelle ou de créer un service concurrent style "Unminus 2.0".
Bref, c'est généreux mais pas non plus l'anarchie.
L'attribution n'est pas obligatoire, mais appréciée et si vous voulez donner un coup de pouce aux artistes, vous pouvez backlinker vers Unminus ou leurs réseaux sociaux. D'ailleurs, le modèle économique repose sur Patreon pour la rémunération des créateurs, ce qui est assez cohérent avec la philo "Yes Artists". C'est fait en Allemagne, hébergé sur SoundCloud pour l'audio, et ça tourne sous Webflow.

Petit bonus, si vous uploadez une vidéo YouTube avec une piste Unminus et que vous vous prenez une réclamation Content ID (ça arrive), le service vous fournit un identifiant de whitelisting pour faciliter la résolution. Enfin, pour ceux qui veulent la qualité maximum, il y a une option pour télécharger en WAV à partir de 5 balles, mais le format gratuit suffit largement pour 99% des usages.
Bref, si vous êtes créateur de contenu et que vous en avez marre de jongler avec les droits d'auteur, Unminus peut clairement vous dépanner. Y'a pas des millions de morceaux, mais c'est propre, gratuit et sans prise de tête. Si vous cherchez d'autres alternatives, j'avais aussi parlé de CChound qui agrège des morceaux Creative Commons, ou vous pouvez consulter ma compilation de ressources de musique libre ici.
Merci à Lorenper pour le tip et bonne écoute à tous !
Remplacez Tux par n'importe quel logo sur le boot de votre Linux
Vous avez déjà rêvé de virer le petit Tux qui s'affiche au démarrage de votre machine Linux pour le remplacer par un truc plus perso ?
Bon OK, sur les distros modernes avec Plymouth ou un bootsplash, on ne le voit plus trop ce logo du kernel... mais si vous bootez en mode console framebuffer, il est bien là ! Petite précision quand même, le logo du kernel ne s’affiche pas magiquement dès qu’on est en "console framebuffer". En fait, pour que ça marche, il faut à la fois que le support de la console framebuffer soit activé dans le kernel (CONFIG_FB_CONSOLE=y) et qu’un framebuffer soit réellement disponible au moment du boot.
Sur les machines modernes, ça passe souvent par simpledrm + KMS, ce qui fonctionne très bien dans la majorité des cas. Mais selon le GPU et le firmware, il arrive encore que l’écran reste noir jusqu’au passage en userspace, même sans Plymouth. Le** logo peut s’afficher**, mais ce n’est pas garanti à 100 % sur toutes les configs.
Bref, c'était possible avant mais fallait se farcir pas mal de bidouille dans les sources du kernel, et c'était pas franchement user-friendly.
Hé bien bonne nouvelle, Vincent Mailhol vient de proposer un patch qui simplifie tout ça !
Du coup, avec ce nouveau patch pour un prochain kernel, vous pouvez spécifier directement le chemin de votre logo personnalisé dans la configuration Kconfig. Fini les bidouilles dans les Makefiles et les sources, y'a maintenant trois options toutes propres : une pour le logo monochrome (format PBM), une pour la version 16 couleurs (PPM), et une pour la version 224 couleurs (PPM aussi). Et c'est à la compilation, que l'outil pnmtologo convertit votre image en code C qui est ensuite directement intégré au kernel. Et ensuite, c'est le framebuffer qui l'affiche au boot comme d'hab.
Et là je me suis dit que ça serait cool de vous proposer mon logo Korben tout prêt, histoire que vous puissiez tester direct. Du coup je vous ai préparé le fichier logo_linux_clut224.ppm au bon format (PPM ASCII 224 couleurs), vous n'avez plus qu'à le télécharger et suivre le tuto ci-dessous.
Ce qu'il vous faut !
Bon alors avant de vous lancer, vérifiez que vous avez les sources du dernier kernel Linux, les outils netpbm pour la conversion d'image, et les trucs de compilation habituels (gcc, make...etc.). Hop, une fois que c'est bon, on peut attaquer.
L'installation rapide (une fois le patch intégré)
Avec le nouveau patch (une fois qu'il sera mergé dans le kernel), c'est devenu hyper simple. Dans menuconfig ou xconfig, allez dans :
Device Drivers -> Graphics Support -> Bootup logo
-> Standard 224-color Linux logo file: /chemin/vers/logo_linux_clut224.ppm
Voilà, vous spécifiez le chemin et c'est réglé. Mais si vous êtes sur un kernel plus ancien, faudra passer par la méthode classique.
La méthode classique (testée sur les kernels 5.x/6.x)
Commencez par installer les dépendances. Sous Debian/Ubuntu :
sudo apt install netpbm build-essential libncurses-dev bison flex libssl-dev libelf-dev
Sous Fedora/RHEL (téléchargez les vraies sources kernel depuis kernel.org) :
sudo dnf install netpbm-progs ncurses-devel elfutils-libelf-devel openssl-devel bc bison flex
Et sous Arch :
sudo pacman -S netpbm base-devel
Ensuite, récupérez les sources du kernel. Soit vous chopez celles de votre version actuelle avec apt source linux-image-$(uname -r), soit vous téléchargez la dernière sur kernel.org. Une fois décompressées, copiez le logo Korben à la place du logo par défaut. Sachez quand même que remplacer directement les fichiers dans drivers/video/logo/ fonctionne très bien pour un test perso, mais ce n’est clairement pas une méthode propre sur le long terme.
Ça complique les mises à jour, ça casse la reproductibilité du build, et c’est totalement inacceptable dans un contexte de packaging distro.
Mais bon, pour bidouiller chez soi, comme on est en train de le faire là, aucun souci. Mais pour un usage propre ou maintenable, mieux vaut éviter… et justement, le fameux patch dont je parlais plus haut va dans ce sens !!
cp /chemin/vers/logo_linux_clut224.ppm drivers/video/logo/logo_linux_clut224.ppm
Maintenant on configure le kernel. Copiez d'abord votre config actuelle avec cp /boot/config-$(uname -r) .config puis lancez make menuconfig. Naviguez vers :
Device Drivers --->
Graphics support --->
[*] Bootup logo --->
[*] Standard 224-color Linux logo
Console display driver support --->
[*] Framebuffer Console support
Assurez-vous que ces options sont cochées avec * (ce sont des booléens, pas des modules).
Ensuite, y'a plus qu'à compiler. Adaptez le -j selon votre nombre de coeurs :
make -j$(nproc)
sudo make modules_install
sudo make install
Sur Debian/Ubuntu, lancez
sudo update-grub
Sur Fedora, c'est
sudo grub2-mkconfig -o /boot/grub2/grub.cfg
Et si votre distro utilise un initramfs, pensez à le régénérer aussi (sudo update-initramfs -u ou équivalent).
Et hop, redémarrez et admirez votre nouveau logo au boot !
Créez votre propre logo
Si vous voulez utiliser une autre image que mon logo Korben, voici comment la convertir au bon format :
sudo apt install imagemagick netpbm
convert mon_logo.png -background white -flatten -colors 224 temp.png
pngtopnm temp.png | ppmquant 224 | pnmtoplainpnm > logo_linux_clut224.ppm
rm temp.png
Le kernel attend un format PPM ASCII (P3) avec maximum 224 couleurs. Pour la taille, pas de contrainte stricte mais entre 80x80 et 200x200 pixels c'est l'idéal. À noter aussi que cette histoire de taille "idéale" reste surtout une recommandation et pas une règle imposée par le kernel car techniquement, Linux ne fixe aucune dimension maximale ou minimale pour le logo. L’image est simplement centrée à l’écran, sans mise à l’échelle.
Là je me suis loupé !
Du coup, un logo trop grand ne sera pas redimensionné mais sera juste rogné ou visuellement dégueu selon la résolution du framebuffer.
Les tailles autour de 80×80 à 200×200 pixels donnent en général le meilleur rendu, mais c’est avant tout du bon sens. Et évitez les dégradés trop complexes vu la limite de couleurs.
Et si ça marche pas ?
Sur les kernels récents (6.x et plus), sachez que simpledrm joue un rôle clé dans l’affichage du logo. En effet, sur beaucoup de machines modernes, il a pris le relais des anciens framebuffer comme efifb et permet d’avoir un affichage très tôt au boot, avant même le lancement de l’userspace.
Donc si le logo ne s’affiche pas alors que tout semble correctement configuré, le problème vient parfois simplement du fait que le framebuffer n’est pas encore actif à ce stade du démarrage, selon le GPU, le firmware ou la façon dont le driver est initialisé.
Autre cause fréquente, Plymouth (ou un autre bootsplash) qui masque tout simplement le logo du kernel. Pour vérifier, vous pouvez désactiver Plymouth temporairement en ajoutant plymouth.enable=0 aux paramètres kernel dans GRUB.
Rnfin, si vous utilisez un driver graphique KMS moderne (ce qui est le cas de la majorité des systèmes actuels), le logo devrait alors s’afficher pendant les toutes premières secondes du boot. En cas d’écran noir persistant, un test ponctuel avec nomodeset peut aider à diagnostiquer le problème, mais ce n’est pas une solution à utiliser systématiquement sur les machines récentes.
Et, pour les problèmes de couleurs bizarres, assurez-vous que votre fichier est bien en format P3 (ASCII) et pas P6 (binaire), quitte à relancer la conversion avec pnmtoplainpnm.
Dernière précision qui évite pas mal de confusions et après j'arrête de vous en faire des tartines, ce logo de boot est directement intégré au kernel, et pas à l’initramfs. Autrement dit, régénérer l’initramfs avec update-initramfs ou équivalent n’a aucun impact sur le logo du kernel. Donc si vous changez le logo, c’est bien le kernel lui-même qu’il faut recompiler et réinstaller.
Bref, perso, je trouve ça super cool qu'on puisse enfin personnaliser ce logo sans se prendre la tête. Ça fait un peu geek old-school c'est vrai, mais y'a un petit côté frime à avoir son propre logo au démarrage de sa bécane, que j'aime bien ^^.
Le logo Gemini oublié dans un trailer Bollywood - La polémique IA la plus ridicule de 2026 (et ça ne fait que commencer)
Vous êtes assis ? Parce que là, on touche le fond du fond du fond des polémiques stupides. Car oui, Internet vient encore de découvrir que l'intelligence artificielle existe... et visiblement, c'est un choc pour pas mal de monde.
Le trailer de Jana Nayagan, le prochain film de la superstar tamoule Vijay, est sorti ce weekend. Et à 23 secondes après le début, pendant une scène où quelqu'un arme un fusil à pompe, les internautes aux yeux de lynx ont repéré un truc : le logo de Google Gemini. Vous savez, la petite étoile à quatre branches. Bref, visiblement quelqu'un aurait utilisé l'IA pour retoucher une image et oublié d'enlever le watermark. C'est con avec mon outil que j'ai développé spécialement pour l'occasion, ça leur aurait pris deux secondes...
![]()
Du coup, Twitter s'est enflammé : "C'est du foutage de gueule. Faut pas que ça devienne normal, l'IA n'a rien à foutre dans les films… et nia nia nia"... Oui des gens sont CHOQUÉS qu'une équipe de production utilise des outils numériques pour créer des images.
Et là, perso, j'ai une question toute bête... Est ce que les gens sont aussi scandalisés quand un graphiste utilise Photoshop ou qu'un musicien utilise un DAW pour composer ? Parce que bon, ça fait 30 ans que le cinéma use et abuse des effets spéciaux numériques, des fonds verts, des retouches en post-prod. Mais là, c'est de l'IA, donc faut croire que c'est une insulte à l'art.
Le plus drôle dans l'histoire c'est que l'équipe du film a réagi au quart de tour. Quand le Hindustan Times a vérifié le trailer dimanche matin, hop, le logo avait disparu. Supprimé comme si de rien n'était. Sauf que le mal était fait, les captures d'écran circulaient déjà partout. Et d'ailleurs, il ne l'ont pas enlevé de la version dispo sur Youtube :
D'ailleurs, petit complot perso que je me suis fait tout seul dans ma tête : Et si c'était fait exprès ? Parce que là, un film tamoul qui aurait eu du mal à faire parler de lui en Occident se retrouve dans les médias tech un peu partout. Buzz gratuit à fond la caisse. Alors marketing de génie ou erreur de stagiaire ? Vous le saurez au prochain épisode.... Toudoum !
Bref, Jana Nayagan sort le 9 janvier en Inde et accessoirement, c'est le 69e et dernier film de Vijay avant qu'il se consacre pleinement à sa carrière politique (il a lancé son parti en 2024 le garçon). Mais tout ça, personne n'en parle. Non, ce qui compte, c'est un petit logo visible une fraction de seconde.
On vit vraiment une époque formidable et moi ça me permet d'alimenter mon site avec ce genre de conneries qui me font bien rire ^^ !
Serflings - Le remake de The Settlers 1 qui va vous replonger en 1993
Vous vous souvenez de The Settlers sur Amiga, ce jeu où vous passiez des heures à regarder vos petits bonhommes transporter du bois, de la pierre et du blé sur des chemins tortueux pendant que votre économie tournait toute seule comme une machine bien huilée ? Ouais, ce jeu-là. Celui qui a ruiné vos week-ends en 1993.
Eh bien un développeur du nom de nicymike a décidé de recréer tout ça from scratch. Serflings , c'est donc un remake complet de The Settlers 1 (aussi connu sous le nom de Serf City: Life is Feudal) codé entièrement en Java. Et quand je dis complet, c'est vraiment complet puisqu'on y retrouve toutes les missions originales avec leurs mots de passe, le mode multijoueur en 1 contre 1 en LAN, et même le support des sauvegardes du jeu original.

Serflings en action ( Source )
Le projet est en développement actif depuis un moment et la version 2.2.0 est sortie fin novembre 2025. Parmi les features qui font plaisir il y a le support des hautes résolutions avec zoom (fini le 320×200 qui pique les yeux), un système de construction de routes intelligent avec preview en temps réel, et la possibilité de jouer sur Windows, macOS ou Linux.
Bon, un truc à savoir quand même, vous aurez besoin des fichiers graphiques originaux pour faire tourner le bouzin, à savoir les fameux SPAE.PA (version anglaise) ou SPAD.PA (version allemande).
C'est parce que les assets appartiennent toujours à Ubisoft, donc nicymike ne peut pas les distribuer avec son remake. Donc si vous avez encore vos disquettes Amiga qui traînent quelque part, c'est le moment de ressortir l'émulateur, sinon, The Settlers History Edition est toujours dispo sur Ubisoft Connect. Y'a pas de petits profits...
Ce que j'aime bien dans ce projet, c'est qu'il ne cherche pas à refaire la roue. C'est vraiment le même gameplay de gestion logistique qui faisait le charme de l'original. Vous construisez des routes, vous placez vos bâtiments, vous optimisez vos flux de ressources, et vous regardez vos petits sujets courir dans tous les sens comme des fourmis sous coke, pendant que votre royaume s'étend. Et 30 ans plus tard, c'est toujours aussi addictif.
Pour ceux qui veulent tester, il vous faudra Java 17 minimum (pour la version 2.x). Vous téléchargez le JAR, vous balancez vos fichiers graphiques dans le bon dossier, et hop c'est parti pour des heures de nostalgie.
Voilà, si vous avez la nostalgie des jeux de gestion des années 90 où on prenait le temps de construire quelque chose de beau au lieu de rusher des objectifs, Serflings mérite clairement le détour.
Jailbreaker son Echo Show pour virer les pubs Amazon et installer Android
Avez-vous un Echo Show qui traîne dans un coin ? Mais si, vous savez, cet écran connecté d'Amazon qui s'est mis à afficher des pubs sur l'écran d'accueil depuis peu. Le genre de truc qui rend dingue 🤪.
Et bien bonne nouvelle puisqu'un développeur nommé Roger Ortiz a trouvé comment libérer ces petites bêtes. Du coup, grâce à ce merveilleux jeune homme, vous pouvez maintenant virer Fire OS, installer LineageOS 18.1 , et faire ce que vous voulez de votre appareil. Hop, plus de pubs, plus de flicage Amazon, juste du bon vieux Android AOSP.

L'Echo Show 8 libéré de Fire OS - enfin un écran connecté qui vous appartient ( Source )
Ce qui a énervé tout le monde de ce que j'ai compris, c'est qu'Amazon a progressivement ajouté des pubs sur ces appareils après leur achat. C'est totalement le genre de pratique qui donne envie de les passer par la fenêtre. Pour le moment, ça fonctionne sur les modèles 2019 comme l'Echo Show 5 (nom de code "checkers") et l'Echo Show 8 (nom de code "crown") car l'exploit cible une faille dans les puces MediaTek de ces appareils. Les versions plus récentes par contre, utilisent un autre processeur, donc pas de chance pour eux.
Le processus de jailbreak se déroule en plusieurs étapes. D'abord, il faut passer l'Echo en mode fastboot en maintenant les trois boutons du dessus au démarrage. Ensuite, on flashe TWRP (le recovery custom bien connu des bidouilleurs Android), on wipe le système, et on installe LineageOS via ADB. Y'a même un package Google Apps optionnel si vous voulez le Play Store.

Attention quand même, le développeur prévient que toute interruption après les 10 premières secondes du flash peut bricker définitivement l'appareil. Donc on ne débranche rien, on ne panique pas, et on attend gentiment les 5 minutes que ça prend.
Une fois Android installé, qu'est-ce qu'on peut en faire ? Déjà, Spotify et Apple Music en versions complètes (pas les versions bridées d'Alexa). Mais le plus intéressant, c'est d'utiliser Home Assistant pour contrôler votre domotique en local. Moins de latence, moins de dépendance aux serveurs Amazon.

Home Assistant qui tourne sur un Echo Show 8 - la domotique locale, sans le cloud ( Source )
D'ailleurs, il y a aussi Music Assistant qui transforme l'Echo en player multiroom compatible Spotify, Apple Music et fichiers locaux, si ça vous chauffe.
Côté specs, faut pas s'attendre à des miracles : 1 Go de RAM et à peine 5,5 Go de stockage. Ça tourne, mais Balatro à 3 FPS c'est compliqué. Par contre, pour de la musique et de la domotique par contre, c'est nickel.
Petit bémol aussi, la caméra ne fonctionne pas encore sous LineageOS, et sur l'Echo Show 5, et le son est limité à un seul haut-parleur pour l'instant. Mais franchement, pour un appareil qu'Amazon a décidé de pourrir avec des pubs, c'est un moindre mal.
Voilà, si ça vous branche de détruire votre Amazon Echo Show ^^, tous les outils et les guides complets sont dispo sur XDA ici ou encore ici ! Et magie magie, votre Echo redeviendra en un claquement de doigts, un appareil qui vous appartient vraiment.
D'où vient le fameux "Hello World" ?
Vous avez déjà écrit un programme qui affiche ces deux mots magiques ?
HELLO WORLDÉvidemment que oui. Tout le monde est passé par là car c'est le rite initiatique universel de la programmation, le premier truc qu'on tape quand on découvre un nouveau langage.
Mais est-ce que vous vous êtes déjà demandé d'où venait cette tradition bizarre de saluer le monde avant de faire quoi que ce soit d'utile ?
Hé bien ça remonte au début des années 70, aux Bell Labs. Brian Kernighan, chercheur canadien qui bossait aux côtés de Dennis Ritchie (le créateur du C) et Ken Thompson, devait rédiger un tutoriel pour le langage B. Le document s'appelait "A Tutorial Introduction to the Language B", et c'est là-dedans que la fameuse phrase apparaît pour la première fois dans un document technique.

Le Hello World original de 1978, imprimé sur papier d'imprimante matricielle ( Source )
{kind=link}
Alors pourquoi ces mots-là et pas autre chose ?
Hé bien Kernighan lui-même a raconté l'anecdote dans une interview pour Forbes India. Il avoue que sa mémoire est un peu floue, mais il se souvient d'un dessin animé avec un poussin qui sortait de son œuf en lançant au monde ce premier message. L'image lui était restée en tête et quand il a dû trouver un exemple à afficher, c'est sorti tout seul.
Marrant non, qu'un des rituels les plus universels de l'informatique mondiale vienne d'un gag de dessin animé avec un poussin. C'est peut-être Calimero, qui sait ?
Ce premier exemple dans le bouquin n'a pas explosé par contre... Suite à cela, il y a eu un autre tutoriel en 1974 (pour le C cette fois), mais c'est vraiment en 1978 avec la publication du livre "The C Programming Language" co-écrit par Kernighan et Ritchie (le fameux K&R que tous les vieux de la vieille connaissent) que c'est devenu LA référence absolue. Ce bouquin a tellement marqué l'histoire que son premier exemple de code est devenu une tradition planétaire.
Voilà, l'anecdote est chouette et je trouve ça génial qu'un truc aussi naze datant des années 70 soit devenu un symbole universel plus de 50 ans après, et cela peu importe le langage !
Flowglad - Gérez vos paiements sans vous prendre la tête avec les webhooks
Vous développez une app et vous devez intégrer des paiements ? Alors vous connaissez sûrement l'enfer des webhooks... Ces petits événements asynchrones qu'il faut capter, parser, dont il faut vérifier la signature, stocker dans votre base, sans oublier de prier pour qu'il n'y ait pas eu de doublon ou de perte entre temps. Bref, le genre de truc qui transforme un samedi après-midi en séance de débogage intensive.
Flowglad c'est une plateforme de paiement open source qui promet d'en finir avec cette galère. Son idée c'est qu'au lieu de synchroniser votre base avec Stripe via des webhooks fragiles, vous interrogez directement Flowglad qui devient votre source de vérité unique pour tout ce qui touche à la facturation.

Du coup, plus besoin de maintenir une table subscriptions en local ni de gérer les cas où un webhook arrive deux fois ou pas du tout. Vous appelez getBilling() côté serveur ou useBilling() côté React, et vous avez l'état de l'abonnement en temps réel. C'est stateless, y'a moins de code à maintenir, et surtout moins de bugs bizarroïdes à traquer à 3h du mat.
Côté fonctionnalités, ça couvre les abonnements classiques, le billing à l'usage avec des tiers de volume, les crédits, la gestion des relances automatiques quand un paiement échoue, la génération de factures... Le SDK gère tout ça avec des hooks React et des fonctions backend en TypeScript. Et comme c'est conçu pour s'intégrer dans votre système d'auth existant, vous utilisez vos propres identifiants utilisateurs, pas ceux de Flowglad.
Dans Flowglad, y'a également le support MCP (Model Context Protocol) qui permet aux agents de code comme Claude Code d'accéder à la documentation et de configurer toute l'intégration. On vit vraiment une époque formidable les amis ^^
Niveau tarifs, c'est du freemium. Le billing/usage, c'est 0,65 % après 1000 $ / mois de volume et pour les transactions Stripe classiques, c'est les frais habituels (2.9% + 0.30$). Sinon, pas de frais mensuels fixes, vous payez à l'usage.
Le projet est soutenu par Y Combinator et tout le code est dispo sur GitHub. Sous le capot c'est du Next.js, tRPC, Drizzle ORM et TypeScript. Pour installer, c'est soit bun add @flowglad/nextjs pour les projets Next.js, soit @flowglad/react + @flowglad/express pour les autres stacks.
Bref, si vous en avez marre de vous battre avec les webhooks de Stripe et que vous cherchez une solution plus propre pour gérer vos abonnements, ça vaut le coup d'y jeter un œil...
Enfant des années 80 - C'était comment la technologie avant Internet ?
Je suis né en 1982. Et si vous êtes né dans ces eaux-là, vous allez comprendre chaque ligne de ce qui suit. Mais si vous avez débarqué sur Terre après l'an 2000, alors accrochez-vous, parce que ce que je vais vous raconter va vous sembler aussi exotique qu'un documentaire sur les hommes préhistoriques, sauf que c'était y'a 35-40 ans, et pas 35 000 ans...
Mais avant, je vous préviens... cet article n'est PAS un "c'était mieux avant" de vieux con nostalgique. Perso, j'adore l'époque actuelle avec nos IA, nos voitures autonomes, Internet, nos ordis qui font des trucs de dingue et nos dirigeants pervers narcissiques psychopathes.
Mais je constate de plus en plus que les moins de 25 ans n'ont aucune idée de comment on survivait avant, donc je veux leur donner un petit aperçu. Parce qu'on a survécu, hein. Et pas si mal que ça, j'trouve.

Une photo flou de moi à l'époque où j'étais encore beau.
Par exemple, aujourd'hui, si vous voulez parler à quelqu'un, c'est facile. Vous sortez votre smartphone !
Mais dans les années 80/90, on avait le téléphone fixe. Un seul pour toute la famille, généralement coincé dans l'entrée ou la cuisine, avec un fil qui vous laissait environ 2 mètres de liberté et un cadran qu'il fallait tourner si vous étiez sur l'ancien modèle...
Et si vous vouliez une conversation privée avec votre crush ? Bah fallait tirer le fil jusqu'à votre chambre pendant que votre petit frère criait "Il parle à son amoureeeeuseee" depuis le salon.
Et les numéros de téléphone, on les trouvait dans ce qu'on appelait un bottin... Oui, les pages jaunes, les pages blanches, dans lesquels y'avait TOUS LES NUMÉROS DE TOUT LE MONDE. Oui, le RGPD ça n'existait pas à l'époque. Et si vous vouliez être sur liste rouge pour que votre numéro ne soit pas dans le bottin, fallait payer.

Jusqu'au milieu des années 70, seul un Français sur sept avait le téléphone chez lui puis on est passé à 20 millions de lignes en 1982... Ça a été super rapide et comme on n'avait pas notre smartphone pour nous sauver, on avait un carnet d’adresses. Un vrai, en papier, avec des numéros écrits à la main. Et surtout, on connaissait les numéros par cœur.
Pas 200, hein… mais les essentiels : Maison, grands-parents, meilleur pote...etc. Aujourd’hui si on vous vole votre téléphone, vous pleurez parce que vous perdez vos photos. Nous, si on perdait un carnet d’adresses, on perdait carrément des gens.
Et quand on était dehors ?
Ben on cherchait une cabine téléphonique. Y'en avait 250 000 en France à la fin des années 90 et aujourd'hui, il n'en reste qu'une poignée.
Même si j'ai aussi connu les cabines à pièces, à mon époque c'était l'arrivée de la télécarte à puce, inventée par un Français en 1976 (cocorico pour Roland Moreno ).

Certains ont même commencé des collections qui valent une blinde aujourd'hui. Le moins génial par contre, c'est qu'il fallait faire la queue derrière quelqu'un qui racontait sa vie pendant que vous attendiez sous la pluie avec une envie de pisser.
Et si vous deviez appeler en urgence, fallait avoir de la monnaie ou une carte. Y'avait pas de "appelle-moi sur mon portable" de fragile, car le portable ça existait pas encore. Par contre, les ancêtres de ça, j'ai nommé le Tamtam, le Tatou et plus tard le Bi-Bop c'était des trucs de bourges donc moi j'ai jamais eu, ni testé.

Sinon, avant d'avoir nos téléphones dans la poche, on avait aussi autre chose que vous connaissez surement et qui s'appelait le Minitel, avec plus de 6 millions de terminaux au début des années 90 et 23 000 services à son apogée.
D'ailleurs, le 3615 ULLA, ça vous dit quelque chose ? Non ? Pourtant, c'est probablement comme ça que vos parents se sont rencontrés. Faut dire que les messageries roses représentaient près de la moitié des connexions Minitel en 1990. On payait 60 francs de l'heure (environ 9 euros) pour draguer par écran cathodique interposé. C'était l'ancêtre de Tinder, mais en beaucoup plus lent et beaucoup plus cher.

Côté divertissement, Netflix et les plateformes de streaming c'est aussi une invention du 21e siècle. Nous, on avait la télévision, avec 6 chaînes si on avait de la chance (TF1, Antenne 2, FR3, La 5, M6, et Canal+ si papa avait le décodeur).
Et la télé, c’était pas juste "j’allume et je regarde". Fallait parfois négocier avec l’antenne râteau, et la "neige" à l’écran faisait partie de la déco. Et puis y’avait le câble Péritel, ce gros connecteur qui vous donnait l’impression de brancher une centrale nucléaire derrière la télé. Sans oublier le télétexte, le truc le plus moche du monde, mais où vous pouviez voir les infos, la météo, et les résultats sportifs en mode pixels de l’enfer. C’était lent, c’était laid… mais c’était déjà un mini-Internet pour les pauvres que nous étions.

Et si vous vouliez regarder un film ? Alors soit vous attendiez qu'il passe à la télé (et vous aviez intérêt à être dispo ce soir-là à 20h50 précises), soit vous alliez au vidéo-club.
Ah, le vidéo-club... Ces temples remplis de cassettes VHS multicolores où on passait 45 minutes à choisir un film qu'on avait déjà vu parce que les nouveautés étaient toujours en rupture. Location à 30 francs, plus l'essence parce qu'il fallait faire des kilomètres pour y aller. Et on lançait toujours un petit coup d’œil vers l'étagère du haut ^^. Et si vous rendiez la cassette en retard ? Paf, y'avait des pénalités. Et si vous oubliiez de rembobiner ? Ouais, des pénalités aussi.

On avait le magnétoscope aussi, format VHS de JVC lancé au Japon en 1976 et arrivé en France dès 1978 (le Betamax de Sony a jeté l'éponge fin des années 80). Et le luxe ultime c'était de pouvoir enregistrer un programme pendant qu'on en regardait un autre. Ou programmer l'enregistrement d'un film qui passait à 2h du mat'. Toutefois, la programmation du magnétoscope était si compliquée que la plupart des cassettes enregistrées contenaient soit du noir, soit la fin d'un autre programme. Personne ne maîtrisait vraiment la bête... ^^

Et pour immortaliser les moments, y’avait le caméscope. Un truc énorme, que votre père tenait comme s’il portait un bazooka. Les vidéos de famille, c’était pas "je filme et je partage en story", non, c’était "je filme", puis "j’achète une cassette", puis "je branche tout au salon", puis "tout le monde regarde en silence pendant 1h30 des plans de vacances où on voit surtout… le sol."
Pour la musique, oubliez Spotify, Apple Music et vos 100 millions de titres accessibles en 2 clics. Nous, on avait les cassettes audio et le Walkman. Sony a sorti le TPS-L2 en 1979 et c'était LA révolution. On pouvait ENFIN écouter SA musique en marchant dans la rue ! Avant ça, la musique c'était soit à la maison, soit à la radio.
Certains Walkman avaient même deux prises casque pour partager avec un pote et un bouton orange "hotline" pour baisser le volume et parler sans enlever ses écouteurs. La classe non ?

Le moins cool par contre, c'était la durée de vie des piles, les bandes qui s'emmêlaient (qui n'a jamais utilisé un crayon pour rembobiner une K7 ?), et le fait qu'on devait acheter un album ENTIER pour avoir les 2-3 morceaux qu'on aimait. Genre vous vouliez "Billie Jean" ? Bah vous achetiez tout l'album Thriller car pas moyen d'avoir le single à 0,99 euro. En même temps, ça nous a permis de découvrir des pépites sur les faces B qu'on n'aurait jamais écoutées sinon.
Après le Walkman, y’a eu aussi le Discman. Le CD, c’était la promesse du "plus de bande qui s’emmêle, qualité parfaite, c'est le futur." Sauf que le futur avait un défaut... vous faisiez deux pas un peu secs et la musique sautait comme une chèvre. Donc vous marchiez comme un ninja pour écouter votre album. Puis ils ont inventé l’anti-choc, et là on s’est tous sentis comme dans un film de science-fiction… à condition de ne pas courir, évidemment.

D'ailleurs, vous voulez une musique bien précise ?
Aujourd'hui vous tapez le titre sur YouTube et c'est réglé en 3 secondes. Mais avant, on attendait des heures devant la radio avec le doigt sur le bouton "REC" du magnéto, prêt à enregistrer dès que le morceau passait. Et évidemment, l'animateur parlait sur l'intro et la fin. TOUJOURS !! Vous vous retrouviez alors sur une compilation de tubes où chaque morceau commençait par "et maintenant sur NRJ, le tube de l'été..." et se terminait par "c'était Madonna avec Like A Virgin, restez avec nous..."
Et pareil pour les clips avec la pub et surtout on ne savait jamais quand est-ce qu'il allait passer.
Bon et maintenant, passons aux jeux vidéo car alors là, gros sujet.
Vous voulez jouer à un jeu aujourd'hui ? No problemo, Steam, GoG, GamePass, téléchargement en quelques minutes, avec des milliers de titres. Alors que dans les années 80-90, on avait les consoles à cartouches comme la NES de Nintendo (1987 en France) ou la Game Boy sortie le 28 septembre 1990 pour la modique somme de 590 francs !

Et je m'en souviens bien, car je l'avais eu pour mon anniv ! 1,4 million vendues la première année en France, un record pour la Game Boy avec son écran vert olive, ses 4 piles AA qui tenaient à peu près 10 heures, et Tetris en bundle.
La concurrence (Game Gear de Sega, Lynx d'Atari) n'a jamais réussi à la détrôner malgré des écrans couleur parce que, ouais, la couleur, ça bouffait les piles en 3 heures.
Et les mises à jour n’existaient pas vraiment. Quand vous achetiez un jeu et qu’il avait un bug, bah… félicitations, vous possédiez un jeu buggé. Pour toujours. Pas de patch "day one", pas de correctif automatique à 3h du matin. Donc soit vous faisiez avec, soit vous espériez qu’un magazine explique une astuce, soit vous recommenciez votre partie en faisant attention à ne pas déclencher LE bug fatal. Aujourd’hui on râle quand une update fait 12 Go, bah nous, on râlait parce qu’on n’avait aucune solution… et que c’était justement ça le problème.
Et avant les consoles perso, y'avait aussi les salles d'arcade. Ces endroits magiques qui puaient la clope et la transpi d'adolescent en stress, remplis de bornes qui bouffaient vos pièces de 1 franc. Street Fighter II, Mortal Kombat, les shoot'em up... Et le truc, c'est qu'on était BONS parce qu'on n'avait pas de continues illimités. Vous mouriez, vous payiez. Du coup on apprenait les combos par cœur, on connaissait chaque pattern des boss alors qu'aujourd'hui on rage-quit au bout de 3 essais.
Nous on avait pas le choix !

Et pour s'informer sur les dernières sorties, pas d'Internet. Mais on avait les magazines. Joystick, Tilt, Player One, Joypad, Generation 4... Ces revues qu'on achetait chaque mois pour avoir les previews, les tests, les soluces (recopiées à la main dans un carnet).

Y'avait aussi les magazines tech comme SVM (Science et Vie Micro) ou Micro Hebdo pour les ordis. Et PC Team aussi ❤️.
Et les magazines, c’était pas juste des tests. C’était parfois… des jeux, des démos, des sharewares, des petits CD (ou disquettes) offerts avec le numéro. Vous découvriez un jeu en version "un niveau gratuit", et si vous aimiez, fallait trouver la version complète comme un quêteur médiéval. Aujourd’hui vous regardez un trailer, vous téléchargez, et si vous n'aimez pas, vous vous faites rembourser en 2 clics.
Alors que nous, on testait un jeu parce qu’il était littéralement collé à la couverture du magazine. La distribution, c’était du papier et de la colle.
On découpait alors les pages avec les cheats codes. On faisait des photocopies pour les potes. Les infos tech arrivaient avec 1 à 3 mois de retard par rapport à leur sortie réelle. Genre le jeu était déjà en rayon que le test sortait le mois d'après... Mais on s'en foutait parce qu'on ne connaissait pas mieux.
Mais maintenant, parlons un peu voyage et navigation. Aujourd'hui vous lancez Google Maps ou Waze et vous arrivez à destination à l'heure ! Et bien nous, avant, on avait la carte Michelin. Ce truc gigantesque qu'il fallait déplier sur le capot de la voiture pendant que papa gueulait parce qu'on avait raté la sortie. La navigation se faisait au co-pilote à base de "à la prochaine, tu prends à droite... non attends... c'est quelle échelle cette carte ?... merde on a dépassé".

On se perdait SYSTÉMATIQUEMENT et on finissait par demander le chemin à un habitant du coin qui vous envoyait dans la direction opposée parce qu'il avait rien compris à notre accent. Et, j'sais pas si vous vous souvenez, mais le Mappy d'époque, c'était le 3615 ITI sur Minitel... si vous aviez le temps bien sûr.
Hé, si ça se trouve, vos parents ont divorcé lors d'une crise de ce genre.
Bon et les photos ??
Aujourd'hui vous mitraillez 47 selfies pour en garder 2. Avant, on avait des appareils jetables et surtout les pellicules !! 24 ou 36 poses. C'est TOUT. Autant dire qu'on réfléchissait fort fort fort avant d'appuyer sur le bouton.
"Est-ce que cette photo vaut vraiment le coup ?"
Et on voyait le résultat... 1 semaine plus tard, après développement chez le photographe. Surprise ! La moitié des photos étaient floues, surexposées, ou avec le doigt de quelqu'un devant l'objectif (systématique pour ma mère).
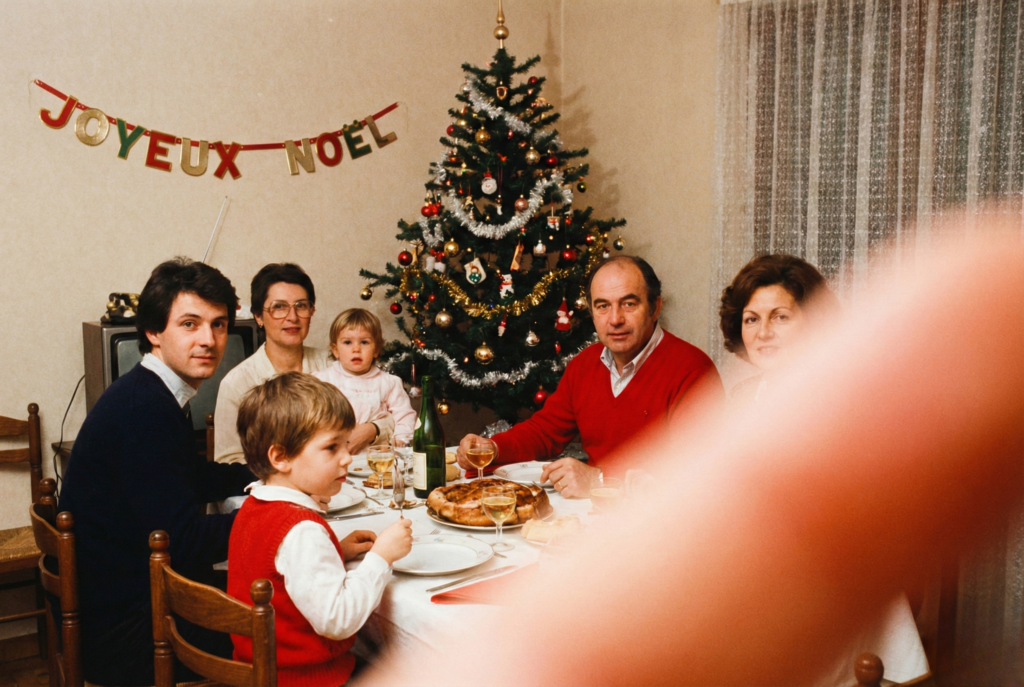
Et on payait quand même le développement. Pas de "supprimer" et recommencer. Par contre, je vous garantis qu'on a des albums photo physiques qui traversent les décennies alors que vos 47 000 photos sur iCloud finiront probablement dans l'oubli.
Et y’avait deux autres délires photo à l'époque. Le Polaroid, d’abord. Vous preniez la photo et vous la voyiez apparaître en direct, comme un tour de magie chimique. Sauf que chaque photo coûtait cher, donc vous trembliez en appuyant sur le bouton. Et à l’inverse, y’avait les diapos... Alors là c’était carrément un événement. On sortait la toile de cinéma, le projecteur, on éteignait la lumière, et on regardait les vacances en format "cinéma du salon"… avec une ampoule qui claquait au pire moment. Nostalgie + odeur de plastique chaud. Le bonheur.
Après l'information en général c'était compliqué. Aujourd'hui, vous voulez savoir un truc, y'a Wikipedia, Google, Perplexity et hop, une réponse en 0,3 secondes. Nous, mis à part le journal télévisé, on avait l'encyclopédie en 24 volumes qui prenait une étagère entière du salon. Ou alors on allait à la bibliothèque municipale faire des recherches pour les exposés. Sans oublier le Quid, ce pavé annuel avec des stats sur tout et n'importe quoi.

Et si on voulait une info très précise ? Ben on demandait à un adulte. Qui inventait probablement la réponse mais on pouvait pas vérifier.
"Papa, c'est quoi la capitale du Burkina Faso ?" "Euh... Tombouctou ?" "OK merci !" (En vrai c'est Ouagadougou).
Et les achats en ligne tels qu'on les connaît ? Quasi inexistants (bon, y'avait le Minitel pour commander, mais c'était pas vraiment pareil). Si vous vouliez un truc, soit vous alliez au magasin, soit vous commandiez sur catalogue (La Redoute, Les 3 Suisses, Quelle... Mesdames, je vous salue... 🎩). Vous entouriez les articles au stylo, vous remplissiez le bon de commande, vous envoyiez par courrier avec un chèque, et vous attendiez 3 à 6 semaines. Soit environ le temps qu'Amazon livre un colis depuis Mars.
Et quand ça arrivait, y'avait une chance sur trois que ce soit pas la bonne taille ou la bonne couleur. Et là, rebelote pour le retour.

Et les devoirs d'école ?
Ah ça non, y'avait pas de ChatGPT, pas de Wikipedia, pas de "copier-coller depuis Internet". On allait à la bibliothèque, on empruntait des bouquins, on prenait des notes à la main, on rédigeait des pages et des pages à la main. Les plus chanceux avaient une machine à écrire et les très très chanceux avaient un ordinateur avec traitement de texte. Mais ça restait rare.
Et devinez quoi ? On arrivait quand même à rendre des devoirs corrects. Incroyable, non ?
Bon, et les rencontres amoureuses ? Pas de Tinder, pas de Meetic, pas de DM Instagram. On draguait EN VRAI. Dans la cour de récré, à la boum du samedi soir (oui, on disait "boum"), en colonie de vacances. On écrivait des mots sur des bouts de papier qu'on faisait passer par les copains. Enfin je dis "On" mais moi j'étais trop timide pour faire ça ^^. Et le summum du romantisme ça restait la mixtape personnalisée qu'on offrait à son crush avec les chansons qui "veulent tout dire".
Et si ça marchait pas ? Ben on attendait la prochaine boum. Notre ghosting à nous c'était de l'évitement physique dans les couloirs du collège. C'était beaucoup plus sportif, croyez-moi.
Et pour se voir entre potes, y’avait un concept incroyable : le rendez-vous fixe. "On se retrouve à 15h devant la FNAC." Et ça, c’était un contrat sacré. Pas de "j’suis en bas", pas de "j’arrive dans 5 minutes", pas de petit point sur une carte. Si vous étiez en retard, l’autre vous attendait… puis il se cassait. Et parfois vous vous loupiez, et c’était terminé. Aujourd’hui, on a des messages illimités. Avant, on avait… la ponctualité et la peur de perdre un ami.
Et puis y’avait LE truc qui vous mettait instantanément dans la catégorie "famille de riches" ou "famille bizarre" et c'était l’ordinateur à la maison. Un vrai hein. Une machine qui prenait la moitié d’un bureau, qui chauffait comme un radiateur et qui faisait un bruit de vaisseau spatial quand elle démarrait. Et encore, "avoir un ordi" ça voulait tout et rien dire car certains avaient un truc pour jouer, d’autres un truc "pour travailler", et dans tous les cas… personne n’avait la moindre idée de ce qu’il faisait vraiment. Mais c’était magique !

Aujourd’hui vous installez un truc et ça marche. Mais à l’époque, installer un logiciel c’était un rite initiatique. Y’avait des commandes à taper, des écrans qui vous parlaient comme un robot dépressif, et des messages du genre "Erreur système" qui nous donnaient envie de nous pendre avec le fil du téléphone fixe. Et quand Windows est arrivé en mode "regardez, c’est facile, y’a des fenêtres", c’était la fête… jusqu’au moment où le PC décidait de planter parce qu'on avait osé brancher une imprimante.
On appelait pas ça "Plug and Play", on appelait ça "Plug and Pray".
Et pour transporter des fichiers… on avait la disquette. Ce carré en plastique qui contenait "toute votre vie" : Un exposé, une sauvegarde, ou le jeu que votre pote vous avait "prêté" (oui oui).
Sauf que la disquette, c’était comme un animal de compagnie anxieux... Si on la posait près d’un aimant, elle mourait lamentablement. Si on la pliait un peu, elle mourait. Si on la regardait de travers, elle mourait. Et quand on faisait une install en plusieurs disquettes, on savait d'avance que le destin allait choisir la numéro 4 pour nous ruiner la soirée.

Puis le jour où on avait un lecteur CD-ROM sur le PC, on devenait un demi-dieu. Parce que d’un coup, on passait de "j’ai un jeu en 12 disquettes" à "j’ai TOUT sur un seul disque". Et surtout… y’avait les encyclopédies sur CD, avec des images, des cartes, parfois même des vidéos. Aujourd’hui ça fait sourire parce que ChatGPT nous répond avant même qu'on finisse une phrase, mais à l’époque voir une animation sur un écran d’ordi, c’était littéralement de la sorcellerie.
Et si vous aviez la chance d’imprimer quelque chose… alors là, bienvenue dans le concert de casseroles grâce à l’imprimante matricielle. Un truc qui faisait un bruit de Kalachnikov asthmatique pendant 12 minutes pour sortir une page en qualité "brouillon de prison". Et le papier, c’était pas des feuilles A4 tranquillement empilées, non, c’était un rouleau infini avec des petits trous sur les côtés, que vous deviez détacher proprement… et que vous déchiriez toujours de travers. La tech, c’était aussi ce genre de bricolage.

Et sur ces ordinateurs, la sauvegarde, c’était pas "tout est dans le cloud". Y'avait même pas de clé USB à l’époque. Non, c’était en mode "j’espère que ça va tenir".
Un disque dur qui claque, et vous perdiez vos photos, vos devoirs, vos trucs importants… sans recours, sans restauration magique, sans "historique des versions". Certains faisaient des copies sur disquettes ou Iomega Zip, d’autres sur des CD, et la plupart… ne faisaient rien. Aujourd’hui on vit dans la redondance, mais avant, on vivait dans le déni, jusqu’au jour où la machine décidait de vous rappeler qui commande.
Et faut être honnête aussi, on copiait tout comme des cochons ! Les cassettes audio, évidemment, mais aussi les jeux, les trucs sur disquettes, puis plus tard les CD quand les graveurs ont commencé à débarquer chez "le pote qui a du matos". C’était pas présenté comme de la cybercriminalité internationale comme aujourd'hui. Non, c’était juste… le quotidien. Un mélange de débrouille, de "je te prête, tu me prêtes", et de compilation faite maison. Aujourd’hui vous payez un abonnement et vous avez tout. Avant, on avait un classeur de CD et c'était notre trésor

Et puis un jour, vers la fin des années 90, y’a eu le modem... C'était l'époque où Internet faisait du bruit. Un bruit de robot qui se noie dans une baignoire, suivi d’un sifflement de dauphin sous crack. Et quand enfin ça se connectait… fallait pas que quelqu’un décroche le téléphone fixe, sinon PAF, coupure et retour à la case départ. Et évidemment, c’était facturé à la durée, donc chaque minute de "surf" vous donnait l’impression de brûler un billet façon Gainsbourg.
Et c'est à partir de là que j'arrêterai ce récit car après, Internet a déboulé et nos vies n'ont plus jamais été les mêmes....
Mais alors, est-ce que c'était mieux avant ?
Honnêtement, non. Mais c'était différent. On avait moins de choix, donc on appréciait plus ce qu'on avait. On s'ennuyait plus, donc on inventait des trucs pour s'occuper. On était moins connectés, donc les moments ensemble étaient plus intenses. Mais je ne changerais pas ma connexion fibre, mon smartphone et mon accès instantané à toute la connaissance humaine contre une télécarte et un magnétoscope. Par contre, je suis content d'avoir connu les deux époques car ça me permet d'apprécier à quel point on a de la chance aujourd'hui !
Car au fond, le vrai changement, c’est pas juste "c’était plus lent". C’est qu’on est passé d’un monde de rareté à un monde d’abondance. Avant, chaque film, chaque album, chaque jeu avait un coût, une logistique qui lui était propre, et provoquait de l'attente. Donc vous choisissiez, vous gardiez, vous rentabilisiez. Aujourd’hui, tout est disponible tout de suite, et le problème n’est plus d’obtenir… c’est de trier.
On a troqué la frustration du manque contre l’épuisement du trop-plein. Et y’a un autre truc aussi qui a changé...
Avant, la tech était matérielle. On possédait des objets comme des cassettes, des VHS, des cartouches, des albums photo, des cartes. Mais aujourd’hui, on possède surtout… des accès. Des comptes, des abonnements, des mots de passe, des licences. C’est génial quand tout marche mais le jour où vous oubliez un identifiant, où votre compte saute, où un service ferme… vous réalisez que vous aviez "tout" sans vraiment rien avoir dans les mains.
On a gagné en confort, mais on a aussi inventé une nouvelle fragilité qui est cette dépendance invisible à un service, à une entreprise.
Mais bon, c'est comme ça, on va pas refaire l'histoire. En tout cas, ces années 80-90, c'était quand même super sympa et j'espère que cette petite plongée dans la nostalgie vous aura plu.
Et si vous n'avez pas connu tout ça, bah maintenant au moins vous savez comment ça se passait pour de vrai.
Ce mod gratuit transforme Breath of the Wild en vrai jeu VR
Vous vous souvenez quand Nintendo a sorti son mode VR pour Breath of the Wild ? Le truc avec les Labo VR Goggles en carton ? Bon, c'était de la stéréo 3D avec suivi de mouvements de tête, mais franchement l'expérience était tellement limitée que pour beaucoup de joueurs, ça ressemblait plus à une démo technique qu'à un vrai mode VR.
Hé bien un moddeur a décidé de faire les choses sérieusement, et le résultat est très impressionnant.

BetterVR transforme Breath of the Wild en véritable expérience VR
Le projet s'appelle BetterVR et c'est exactement ce que ça veut dire. Fini les limitations du mode Nintendo Labo, ici on parle de vrai rendu stéréo en 6DOF (six degrés de liberté) avec support complet des mains et des bras. Vous pouvez dégainer vos armes en tendant le bras derrière votre dos, attaquer en faisant des mouvements de bras, couper du bois en mimant les gestes... Bref, c'est Hyrule comme si vous y étiez vraiment.
Le truc de dingue, c'est que le moddeur Crementif a bossé dessus pendant cinq ans, avec l'aide de quelques contributeurs pour les tests. Le résultat tourne sur l'émulateur Cemu (version 2.6 minimum) et fonctionne avec les casques VR compatibles OpenXR. Les contrôleurs Oculus Touch sont configurés par défaut, pour les autres (Index, Vive) il faudra probablement faire un remappage manuel via SteamVR.
Pour en profiter, il vous faudra évidemment une copie légale de Breath of the Wild version Wii U (oui, c'est important de le préciser), un PC qui tient la route avec un bon CPU single-thread, et Windows parce que ça ne fonctionne pas sous Linux pour l'instant. J'avais déjà parlé d'un portage VR de Zelda à l'époque de l'Oculus Rift, mais c'était sur la version NES et franchement ça donnait plus le mal de mer qu'autre chose. Là, on est sur un autre niveau.
Ce qui m'impressionne au-delà de la technique, c'est que le mod ne contient aucun fichier du jeu original. Il fonctionne via un hook (des fichiers dll/json/bat) qui intercepte le rendu et active un graphic pack Cemu.
Et est-ce que ça change quoi que ce soit légalement ? Avec Nintendo, vaut mieux pas trop compter là dessus, donc si ça vous tente, autant tester pendant que c'est encore là.
L'installation demande quelques prérequis : Cemu 2.6 ou plus récent, BotW avec l'update V208, Vulkan activé et VSync désactivé. Ensuite vous téléchargez le mod depuis le GitHub , vous extrayez dans le dossier Cemu, vous lancez Cemu une première fois normalement, puis vous utilisez le fichier batch pour lancer en mode VR. Les graphic packs BetterVR et FPS++ s'activeront alors automatiquement...
Perso je trouve ça cool de voir que la communauté arrive à faire en quelques années ce que Nintendo n'a jamais voulu développer sérieusement.

La dernière version (0.9.3) vient de sortir avec pas mal d'améliorations. Il y a même un mode troisième personne si vous préférez garder vos distances avec les Lynels (même si c'est encore un peu buggé).
Parce que bon, se faire charger par un centaure géant en vue subjective, ça doit quand même faire son petit effet.
Bref, si vous avez un casque VR qui traîne et que vous n'avez jamais vraiment exploré Hyrule comme vous l'auriez voulu, c'est l'occasion ou jamais. En attendant que Nintendo daigne sortir un vrai jeu Zelda en VR (on peut toujours rêver), au moins les moddeurs sont là pour combler le vide.